Hierarchical Action Classification with Network Pruning
Mahdi Davoodikakhki
KangKang Yin
Research on human action classification has made significant progresses in the past few years. Most deep learning methods focus on improving performance by adding more network components. We propose, however, to better utilize auxiliary mechanisms, including hierarchical classification, network pruning, and skeleton-based preprocessing, to boost the model robustness and performance. We test the effectiveness of our method on four commonly used testing datasets: NTU RGB+D 60[1], NTU RGB+D 120[2], Northwestern-UCLA Multiview Action 3D[3], and UTD Multimodal Human Action Dataset[4]. Our experiments show that our method can achieve either comparable or better performance on all four datasets. In particular, our method sets up a new baseline for NTU 120, the largest dataset among the four. We also analyze our method with extensive comparisons and ablation studies
Method
Here, we briefly describe our method and encourage the readers to read our paper[5] for deeper explanations.
Network Model
We build our network on top of the Glimpse Clouds network[6] and take advantage of cropping the area around people in the video (video cropping), Hierarchical Classification, and Network Pruning to improve the accuracy. Hierarchical Classification could help with extracting more meaningful features in the initial stacks and Network Pruning could be beneficial in overcoming overparameterization.
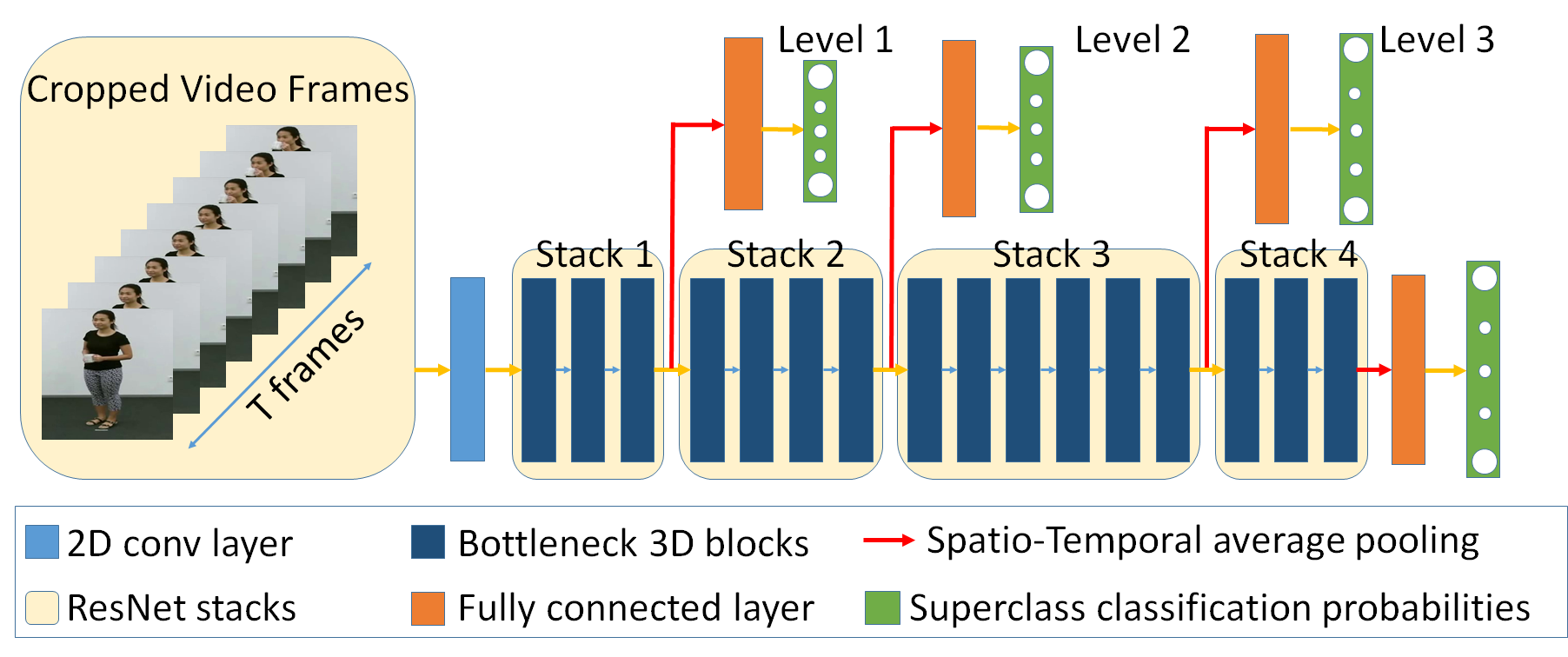
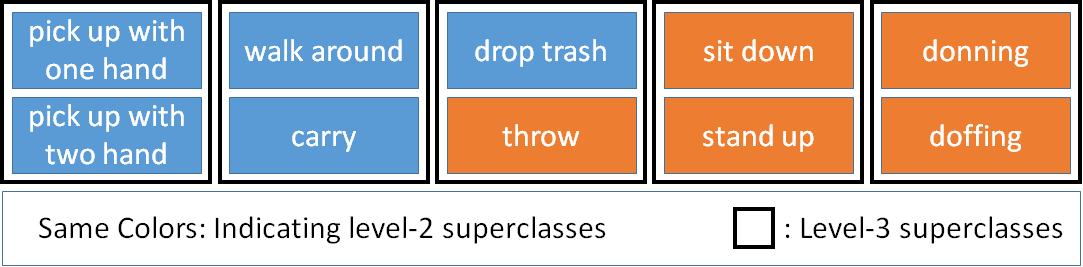
Superclasses
To encourage our network in extracting features gradually, we make 4 levels each containing superclasses, which have the same number of classes in each level. We first train our model without any hierarchical classification and obtain the similarities among the classes. We then try to put the most similar classes in the same superclass to make the classification easier on levels and gradually make the task harder. To obtain the superclasses, we uniformly put the classes randomly in superclasses and then use a greedy algorithm to change the swap the classes that have the most effect in decreasing similarities between superclasses.
We continue the algorithm until no improvement could be achieved. We also repeat the algorithm 1000 times and use the best obtained result for the superclasses configuration in each level.
Results
Here, we compare our method with the recent publications. We have achieved state-of-the-art results in most comparisons. We have provided more analysis and ablation studies on the backpropagated gradients, superclasses size, and percentage of pruning in our paper and we again encourage the readers to look at our paper for more details.[5]
| Method | Year | Pose Input | RGB Input | Cross-View | Cross-Subject |
|---|---|---|---|---|---|
| Glimpse Clouds[6] | |||||
| FGCN[7] | |||||
| MS-G3D Net[8] | |||||
| PoseMap[9] | |||||
| MMTM[10] | |||||
| Action Machine[11] | |||||
| PGCN[12] | |||||
| Ours |
| Method | Year | Pose Input | RGB Input | Cross-View | Cross-Subject |
|---|---|---|---|---|---|
| Action Machine[11] | |||||
| TSRJI[13] | |||||
| PoseMap from Papers with Code[14] | |||||
| SkeleMotion[15] | |||||
| GVFE + AS-GCN with DH-TCN[16] | |||||
| Glimpse Clouds[6] | |||||
| FGCN[7] | |||||
| MS-G3D Net[8] | |||||
| Ours |
| Method | Year | Pre-trained | Pose Input | RGB Input | Cross-Subject |
|---|---|---|---|---|---|
| Glimpse Clouds[6] | |||||
| JTM[17] | |||||
| Optical Spectra[18] | |||||
| JDM[19] | |||||
| Action Machine Archived Version[20] | |||||
| PoseMap[9] | |||||
| Ours[21] |
| Method | Year | Pre-trained | Pose Input | RGB Input | View1 | View2 | View3 | Average |
|---|---|---|---|---|---|---|---|---|
| Ensemble TS-LSTM[22] | ||||||||
| EleAtt-GRU(aug.)[23] | ||||||||
| Enhanced Viz.[24] | ||||||||
| Glimpse Clouds[6] | ||||||||
| FGCN[7] | ||||||||
| Action Machine[11] | ||||||||
| Ours |
References
[1]Shahroudy, A., Liu, J., Ng, T., Wang, G.: Ntu rgb+d: A large scale dataset for 3d human activity analysis. In: CVPR. pp. 1010–1019 (2016)
[2]Liu, J., Shahroudy, A., Perez, M.L., Wang, G., Duan, L.Y., Kot Chichung, A.: Ntu rgb+d 120: A large-scale benchmark for 3d human activity understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence (2019)
[3]J. Wang, X. Nie, Y. Xia, Y. Wu, and S. Zhu. Cross-view action modeling, learning, and recognition. IEEE Conference on Computer Vision and Pattern Recognition, pages 2649–2656, 2014.
[4]C. Chen, R. Jafari, and N. Kehtarnavaz. Utd-mhad: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In IEEE International Conference on Image Processing, pages 168–172, 2015.
[5]Hierarchical Action Classification with Network Pruning, Mahdi Davoodikakhki and KangKang Yin. 15th International Symposium on Visual Computing (ISVC 2020).
[6]Fabien Baradel, Christian Wolf, Julien Mille, and Graham W. Taylor. Glimpse clouds: Human activity recognition from unstructured feature points. IEEE Conference on Computer Vision and Pattern Recognition, 2018.
[7]Hao Yang, Dan Yan, Li Zhang, Dong Li, YunDa Sun, ShaoDi You, and Stephen J. Maybank. Feedback graph convolutional network for skeleton-based action recognition, 2020.
[8]Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, and Wanli Ouyang. Disentangling and unifying graph convolutions for skeleton-based action recognition, 2020.
[9]M. Liu and J. Yuan. Recognizing human actions as the evolution of pose estimation maps. In IEEE Conference on Computer Vision and Pattern Recognition, pages 1159–1168, 2018.
[10]Hamid Reza Vaezi Joze, Amirreza Shaban, Michael L. Iuzzolino, and Kazuhito Koishida. Mmtm: Multimodal transfer module for cnn fusion, 2019.
[11]Jiagang Zhu, Wei Zou, Zhu Zheng, Liang Xu, and Guan Huang. Action machine: Toward person-centric action recognition in videos. IEEE Signal Processing Letters, PP, 2019.
[12]Lei Shi, Yifan Zhang, Jian Cheng, and Han-Qing Lu. Action recognition via pose-based graph convolutional networks with intermediate dense supervision. ArXiv, abs/1911.12509, 2019.
[13]Carlos Caetano, Francois Bremond, and William Robson Schwartz. Skeleton image representation for 3d action recognition based on tree structure and reference joints. SIBGRAPI Conference on Graphics, Patterns and Images, 2019.
[14]M. Liu and J. Yuan. Recognizing human actions as the evolution of pose estimation maps. https://paperswithcode.com/paper/recognizing-human-actions-as-the-evolution-of. Accessed: 2020-05-12.
[15]Carlos Caetano, Jessica Sena, Franeois Bremond, Jefersson A. Dos Santos, and William Robson Schwartz. Skelemotion: A new representation of skeleton joint sequences based on motion information for 3d action recognition. IEEE International Conference on Advanced Video and Signal Based Surveillance, 2019.
[16]Konstantinos Papadopoulos, Enjie Ghorbel, Djamila Aouada, and Björn Ottersten. Vertex feature encoding and hierarchical temporal modeling in a spatial-temporal graph convolutional network for action recognition, 2019.
[17]Pichao Wang, Zhaoyang Li, Yonghong Hou, and Wanqing Li. Action recognition based on joint trajectory maps using convolutional neural networks. ACM International Conference on Multimedia, 2016.
[18]Y. Hou, Z. Li, P. Wang, and W. Li. Skeleton optical spectra-based action recognition using convolutional neural networks. IEEE Transactions on Circuits and Systems for Video Technology, 28(3):807–811, 2018.
[19]C. Li, Y. Hou, P. Wang, and W. Li. Joint distance maps based action recognition with convolutional neural networks. IEEE Signal Processing Letters, 24(5):624–628, 2017.
[20]Jiagang Zhu, Wei Zou, Liang Xu, Yiming Hu, Zheng Zhu, Manyu Chang, Junjie Huang, Guan Huang, and Dalong Du. Action machine: Rethinking action recognition in trimmed videos, 2018.
[21]Hierarchical Action Classification with Network Pruning, Mahdi Davoodikakhki and KangKang Yin. ArXiv, 2020
[22]Lee, I., Kim, D., Kang, S., Lee, S.: Ensemble deep learning for skeleton-based action recognition using temporal sliding lstm networks. In: ICCV. pp. 1012–1020 (2017)
[23]Pengfei Zhang, Jianru Xue, Cuiling Lan, Wenjun Zeng, Zhanning Gao, and Nanning Zheng. Adding attentiveness to the neurons in recurrent neural networks. In Proceedings of the European Conference on Computer Vision, pages 135–151, 2018.
[24]Mengyuan Liu, Hong Liu, and Chen Chen. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognition, 03 2017.